
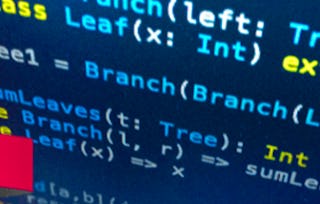
使用函数式概念来处理分布在集群上的大数据在工业领域非常普遍,可以说这是函数式思想在工业领域的首次广泛应用。MapReduce 和 Hadoop,以及最近用 Scala 编写的快速、内存分布式集合框架 Apache Spark 的流行就证明了这一点。在本课程中,我们将了解如何使用 Spark 将数据并行范式扩展到分布式情况。我们将详细介绍 Spark 的编程模型,仔细了解它与我们熟悉的编程模型(如共享内存并行集合或顺序 Scala 集合)的不同之处和不同时间。通过 Spark 和 Scala 中的实践示例,我们将了解何时应考虑延迟和网络通信等与分布相关的重要问题,以及如何有效解决这些问题以提高性能。 学习成果。本课程结束时,您将能够:- 从持久化存储中读取数据并将其加载到 Apache Spark 中,- 使用 Spark 和 Scala 操作数据,- 以函数式风格表达数据分析算法,- 认识如何在 Spark 中避免洗牌和重新计算:您应该至少有一年的编程经验。熟练掌握 Java 或 C# 是理想的选择,但熟练掌握其他语言(如 C/C++、Python、Javascript 或 Ruby)也足够了。您应该熟悉使用命令行。本课程适合在《并行编程:https://hua.dididi.sbs/learn/parprog1》之后学习。
使用 Scala 和 Spark 进行大数据分析
91%
of learners achieved a positive career outcome
了解顶级公司的员工如何掌握热门技能

积累特定领域的专业知识
本课程是 Scala 中的函数式编程 专项课程 专项课程的一部分
在注册此课程时,您还会同时注册此专项课程。
- 向行业专家学习新概念
- 获得对主题或工具的基础理解
- 通过实践项目培养工作相关技能
- 获得可共享的职业证书

该课程共有4个模块
获得职业证书
将此证书添加到您的 LinkedIn 个人资料、简历或履历中。在社交媒体和绩效考核中分享。
位教师
授课教师评分
(153个评价)
从 算法 浏览更多内容
École Polytechnique Fédérale de Lausanne



人们为什么选择 Coursera 来帮助自己实现职业发展

Felipe M.
自 2018开始学习的学生
''能够按照自己的速度和节奏学习课程是一次很棒的经历。只要符合自己的时间表和心情,我就可以学习。'

Jennifer J.
自 2020开始学习的学生
''我直接将从课程中学到的概念和技能应用到一个令人兴奋的新工作项目中。'

Larry W.
自 2021开始学习的学生
''如果我的大学不提供我需要的主题课程,Coursera 便是最好的去处之一。'

Chaitanya A.
''学习不仅仅是在工作中做的更好:它远不止于此。Coursera 让我无限制地学习。'
学生评论
- 5 stars
73%
- 4 stars
21.03%
- 3 stars
4.42%
- 2 stars
0.65%
- 1 star
0.88%
显示 3/2600 个
CC
已于 Jun 7, 2017审阅
The sessions where clearly explained and focused. Some of the exercises contained slightly confusing hints and information, but I'm sure those mistakes will be ironed out in future iterations. Thanks!
MT
已于 Aug 5, 2019审阅
the theory is very clear and well explained.the practical assignments are a little bit ambiguous but they are overall very good and challenging. highly recommended!
CH
已于 Nov 16, 2017审阅
although spark part is taught nicely, it also takes a lot of time to understand the sql part and remember a lot of sql operations as a zero background man in sql
通过在线学位推动您的职业生涯
获取世界一流大学的学位 - 100% 在线



